【摘要】 谷歌开源Live Transcribe的语音引擎 可用70多种语言和方言实时口语
8月18日,谷歌宣布开源Android语音识别转录工具Live Transcribe的语音引擎。
这家公司希望这样做可以让任何开发人员为长篇对话提供字幕,减少因网络延迟、断网等问题导致的沟通障碍。源代码现在可以在GitHub上获得。这意味着无论你是出国或是与新朋友见面,Live Transcribe都可以帮助你进行沟通。
 交流时可以实时畅通(只要有网络)
交流时可以实时畅通(只要有网络)谷歌于今年2月发布了Live Transcribe。该工具使用机器学习算法将音频转换为实时字幕,与Android即将推出的Live Caption功能不同,Live Transcribe是一种全屏体验,使用智能手机的麦克风(或外接麦克风),并依赖于Google Cloud Speech API。Live Transcribe可以用70多种语言和方言标题实时口语。另一个主要区别是Live Transcribe可在18亿台Android设备上使用(当Live Caption在今年晚些时候推出时,它只适用于部分Android Q设备)。
在云上工作
谷歌的Cloud Speech API目前不支持发送无限长的音频流。此外,依赖云意味着网络连接、数据成本和延迟方面都有潜在问题。
结果,语音引擎在达到超时之前关闭并重新启动流请求,包括在长时间静默期间重新开始会话并且每当语音中检测到暂停时关闭。在会话之间,语音引擎还在本地缓冲音频,然后在重新连接时发送它。因此,谷歌避免了截断的句子或单词,并减少了会话中丢失的文本量。
 70多种语言和方言中挑选自己合适的
70多种语言和方言中挑选自己合适的为了降低带宽需求和成本,谷歌还评估了不同的音频编解码器:FLAC,AMR-WB和Opus。FLAC(无损编解码器)可以保持准确性,不会节省太多数据,并且具有明显的编解码器延迟。AMR-WB可以节省大量数据,但在嘈杂的环境中准确度较低。
与此同时,Opus允许数据速率比大多数音乐流媒体服务低许多倍,同时仍保留音频信号的重要细节。谷歌还会在长时间的静音期间使用语音检测来关闭网络连接。
总体而言,该团队能够实现“在不影响准确性的情况下,将数据使用量减少10倍”。
为了比Cloud Speech API更进一步减少延迟,Live Transcribe使用自定义Opus编码器。编码器恰好提高了比特率,使“延迟在视觉上无法区分发送未压缩的音频”。
Live Transcribe语音引擎功能
谷歌列出了语音引擎的以下功能(不包括说话人识别):
无限流媒体。
支持70多种语言。
可以简化网络丢失(在网络和Wi-Fi之间切换时)。文字不会丢失,只会延迟。
强大的扩展网络损耗。即使网络已经停电数小时,也会重新连接。当然,没有连接就不能进行语音识别。
可以轻松启用和配置Opus,AMR-WB和FLAC编码。
包含文本格式库,用于可视化ASR置信度、发言人ID等。
可离线模型扩展。
内置支持语音检测器,可在延长静音期间用于停止ASR,以节省资金和数据。
内置支持扬声器识别,可根据扬声器编号标记或着色文本。
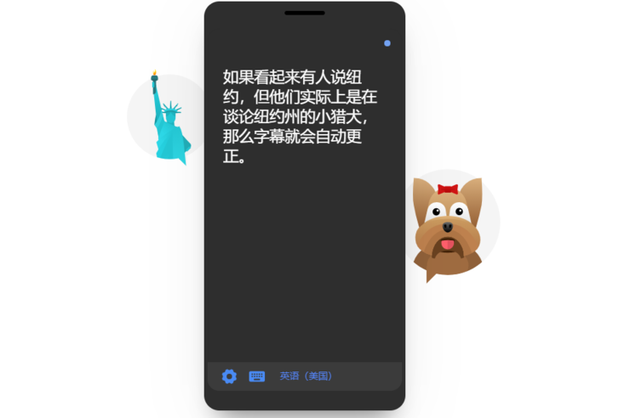 字幕会随着对话的深入而调整
字幕会随着对话的深入而调整该文档指出这些库与生产应用程序Live Transcribe中运行的库“几乎相同”。谷歌已对其进行了“广泛的现场测试和单元测试”,但测试本身并非开源。但谷歌确实提供了APK,因此开发者可以在不构建任何代码的情况下试用该库。